At cVation we have a strong DevOps focus, aiming to address tasks with a customer-centric approach. Our main goal is to reconcile the interests of development and operations, even when they clash (e.g., the desire for unrestricted launches versus the reluctance to change a working system).
Site Reliability Engineering
SRE was pioneered by Google, where it was developed to manage their large-scale systems. However, the principles and practices of SRE as an engineering discipline have been adopted by many other organizations to improve the reliability of their software systems.
In summary, SRE is a set of practices and principles which combines software engineering and operations to ensure the reliability, performance, and availability of complex software systems through the use of automation, monitoring, incident response and continuous improvement.
Site Reliability Engineering (SRE) is devoted to help organizations sustainable achieve the proper level of reliability in their systems. An important aspect, is to find the right balance between agility and stability.
Responsibilities of the SRE teams are:
Availability / reliability / latency / performance / efficiency / change management / monitoring / emergency response and capacity planning of their services.
To allow a team to do this on a large project we aim to automate or cut out anything repetitive. The SRE team will emphasize that the systems design will work reliably amidst frequent updates from development teams.
For the SRE team to be able to adapt to a changing system, it needs to be designed with observability in mind, i.e., having a high level of monitoring which means logging enough data in the system to be able to do proper investigations. This allows the SRE team to constantly assess new user flows and monitor critical paths for the project.
Agility versus Stability
Historically the division between Development and Operation has resulted in a clash of what is most important: Either agility in releasing new features or maintaining stability for the customer.
The SRE concept allows us to discuss this conundrum, by utilizing Service Level Indicators (SLIs), Service Level Objectives (SLOs) and a resulting error budget. The SLI can be interpreted as monitoring an important user flow, e.g., in an IoT setup. Here it could be the user installing a sensor and confirms it being alive in a management portal. The SLO would then be the rules for latency, availability, and correctness that the user should expect.
The SLO allows the SRE team and the business to communicate and agree on concrete numbers of uptime and performance. The difference between the measured SLI and the defined SLO is the error budget. When we are performing better than agreed the development teams can ship features ASAP. However as soon as our budget is negative, the SRE team is charged with halting releases, investigating issues, removing or tasking a development team to remove impediments. Basically, a negative SLO means that the project needs to focus on quality. Thus, the battle between operation and development can be reduced to being over or under our agreed SLO.
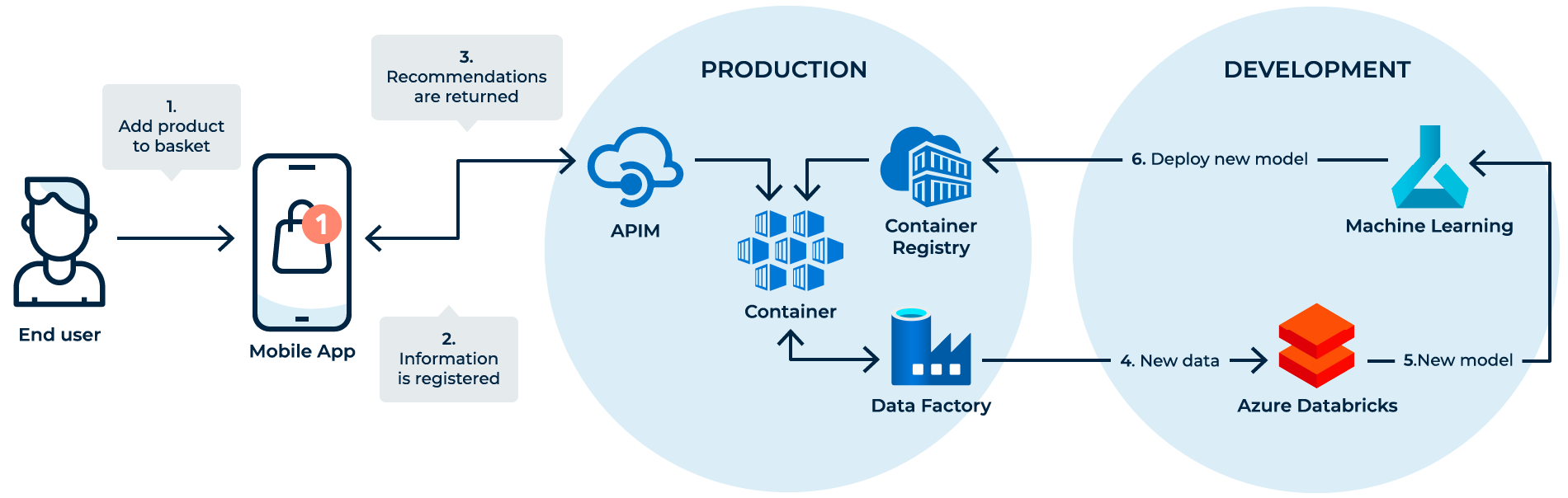
To explicitly define the error budget, we can interpret it as how much “unreliability” is available in the measured time frame. This is an important notion, since all deployments introduce a risk for unreliability, even the biggest companies such as Microsoft can release something that despite all tests and best practices can result in an outage. The SRE team is often seen as only focusing on user-flows related to availability or latency, but a user-flow could also be seen from a business perspective such as revenue or churn. Let us examine this with the following example, where we have a Machine Learning setup which generates recommendations for our users.