Hos cVation arbejder vi aktivt med kvalitetssikring. Det gør vi i høj grad gennem automatiserede tests, som både hjælper os med at sikre forretningslogikken her og nu, men også beskytter os mod regressioner i fremtiden. Når vi udvikler nye features bliver de akkompagneret af en række tests som sikrer, at den nye kode fungerer som den skal i forskellige situationer. Når testene går godt, kan vi læne os tilbage i stolen, klappe os selv på skuldrene og være sikre på at koden har en høj kvalitet. Eller hvad?
Hvordan kan man med ro i maven stole på sine tests? De tests vi har lavet er jo også kode, og den kode kunne – ligesom koden vi forsøger at kvalitetssikre – indeholde fejl. Hvordan ved vi, at de automatiserede tests tester det, vi forventer? Kan vores tests overhovedet fange defekter, vi ikke selv har kunnet forudsige? Hvordan kvalitetssikrer vi vores kvalitetssikring?
Code coverage
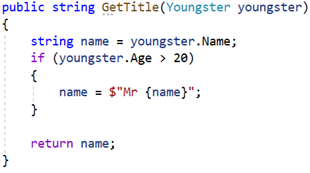
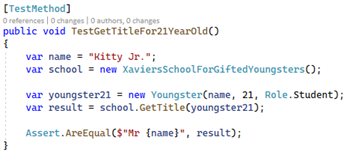
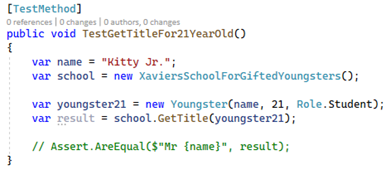
Vi kunne skrive nye tests af vores tests, men for at undgå denne uendelige rekursion må vi finde på noget bedre. Her bruger mange code coverage. Dette koncept handler om at måle, hvor stor en del af koden, der rammes gennem de eksisterende tests. Lad os tage fat i et konkret eksempel. Denne simple metode tager imod en person og returnerer personens titel. Metoden er tiltænkt at returnere personens navn med ”Mr. ” foran, hvis personen er 21 år eller ældre: